
|
|
Threading |
See also Performance Docs |
This document will give you an overview between the relationship of the threading models used by the SolarisTM operating environment and the JavaTM thread model. Choices you make about Solaris threading models can have a large impact on the performance of your Java runtime enivonment on Solaris operating environment.
The Java programming language is naturally multi-threaded and because of this the underlying OS implementation can make a substantial difference in the performance of your application. Fortunately (or unfortunately), you can choose from multiple threading models and different methods of synchronization within the model, but this varies from VM to VM. Adding to the confusion, the threads library will be transitioning from Solaris 8 to 9, eliminating many of these choices.
Version 1.1 is based on green threads and won't be covered here. Green threads are simulated threads within the VM and were used prior to going to a native OS threading model in 1.2 and beyond. Green threads may have had an advantage on Linux at one point (since you don't have to spawn a process for each native thread), but VM technology has advanced significantly since version 1.1 and any benefit green threads had in the past is erased by the performance increases over the years.
Two different threading models are available in Solaris, a many-to-many model and a one-to-one model. Many-to-many and one-to-one refer to (essentially) LWPs (lightweight processes) and Solaris Threads. Each LWP has a kernel thread, but once on an LWP the kernel will schedule you on a cpu. If you are in a thread, the thread library must schedule you on an LWP before you make it to a cpu. Why would this be an advantage? Because there is a lot more state and kernel resources used if there are many LWPs, so fewer LWPs keeps the kernel light and nimble and improves performance. Why would this be a disadvantage? It's possible that you can get thread starvation if the thread doesn't get scheduled on an LWP in an adequate amount of time.
Looking at the following figure:
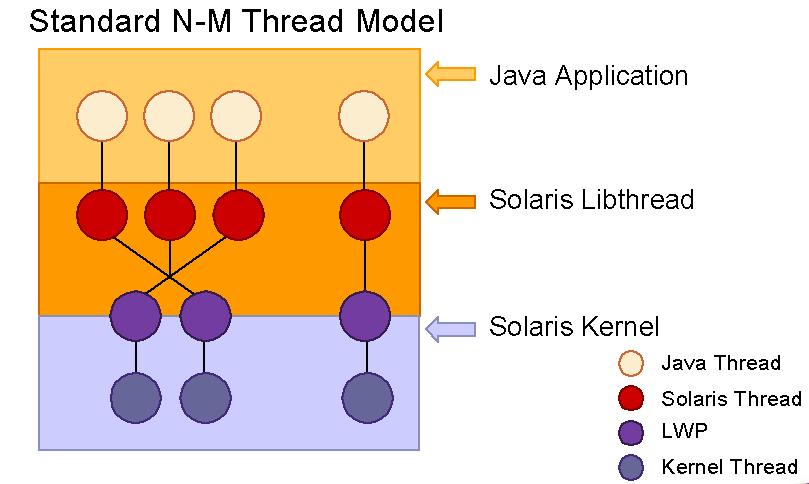
Java threads are really Solaris Threads since we've been using the native OS threading model in the 1.2 VM. The left side shows the many-to-many model, where Solaris threads are scheduled by the Solaris libthread.so library to run on LWPs. The LWPs are one-to-one with kernel threads. The right hand side shows a one-to-one model, which marries Solaris threads with LWPs. This creates more LWPs (since one must exist for each thread), and we'll explore the effects later.
The many-to-many model is the default in pre-Solaris 9. Solaris 8 offers an "alternate" threading library for a true one-to-one model, but before Solaris 7 you can only use the many-to-many model (or fake it with bound threads). Just to throw in a little more confusion, when creating Solaris threads, one can specify that the thread be bound to an LWP for its entire life. This effectively creates a one-to-one model, but has some overhead which we'll also explore later.
So, let's review our options, remember that not all of these are relevant to all J2SE releases or even versions of the Solaris OS.
| Feature | pre-Solaris 8 | Solaris 8 | Solaris 9 |
| Many-to-Many, thread based synchronization | 1.3*,1.4 | 1.3*,1.4 | Not Available |
| Many-to-Many, lwp based synchronization | 1.2*,1.3,1.4* | 1.2*,1.3,1.4* | Not Available |
| One-to-One, via Bound threads | 1.3,1.4 | 1.3,1.4 | Not Available |
| One-to-One, via Alternate Threads library | Not Available | 1.2,1.3,1.4 | 1.2*,1.3*,1.4* |
*:Note: The default model for this VM
While reading this table, realize that certain Solaris OS versions will not allow something that is capable in the VM. For example, even though the VMs can all use the one-to-one model via the alternate threads library, its not available on Solaris 7. Also, you can figure out that the alternate thread library in Solaris 8 will become the only thread library in Solaris 9, which means the many-to-many model will be officially retired. This means that the many-to-many model, available in J2SE version 1.2, 1.3, and 1.4, cannot be utilized with Solaris 9.
What may seem somewhat disturbing in Solaris 9, the deletion of threading model options, has actually simplified things quite a bit, and the performance thus far has been excellent, with only the most severely tuned code degrading, and most improving by a good margin. Give the alternate threads library a try, since they are available now in Solaris 8. The good news is that it is not necessary to recompile your code, the interfaces all remain the same and using the alternate threads library in Solaris 8 is accomplished by simply changing your LD_LIBRARY_PATH to include /usr/lib/lwp
| Feature | 1.2 option | 1.3 option | 1.4 option |
| Many-to-Many thread based synchronization | n/a | default | -XX:-UseLWPSynchronization |
| Many-to-Many lwp based synchronization | default | -XX:+UseLWPSynchronization | default |
| One-to-One via bound threads | n/a | -XX:+UseBoundThreads | -XX:+UseBoundThreads |
| One-to-One via Alternate Libthread* | export LD_LIBRARY_PATH=/usr/lib/lwp | export LD_LIBRARY_PATH=/usr/lib/lwp | export LD_LIBRARY_PATH=/usr/lib/lwp |
We have found two problems with the default model in 1.3, but have the options above in order to get around them.
In general, the many-to-many model with thread based synchronization is fine, although in rare cases we've seen thread starvation with moderate numbers of threads (somewhere near the number of cpus). In one study we slowly increased the numbers of threads on the system up to 2x the number of cpus and had each thread doing an equal amount of work. We then measured the difference between the thread doing the most work to the thread doing the least work, and found that with with the "alternate" libthread on Solaris 8 that the difference went to 8% from 29%. Performance, however, was not affected by that much (1-2%). This experiment taught us that the thread model does not generally make a performance difference, but when seeing thread starvation try using any of the alternative models. You'll note that in 1.2, lwp based synchronzation was the default, so it doesn't suffer from thread starvation.
The other problem is with scalability. Another form of thread starvation, we've found
that there are not enough LWPs created to deal with large numbers of threads. In studies
looking at 30 cpu machines running with 2000 threads, we found that the ratio of Solaris Threads
to LWPs was around 2:1, but that this severely restricted the throughput of compute bound applications.
LWPs are usually created when threads block in the kernel, but if your application doesn't block
and simply performs computation, you can see reduced performance.
When using -XX:+UseLWPSynchronization, the ratio went to 1:1, which gives
us 1 LWP for every Solaris Thread, although those threads are not bound to the LWPs (they
can hop around from LWP to LWP). This produced a 7x throughput. Moving to a one-to-one
model via bound threads, which you might expect to be the same as LWP synchronization
since we have a 1:1 ratio between LWPs and Solaris Threads, showed a decrease of over
80% (worst case). This was unexpected, but there must be some pretty bad overhead
when binding the Solaris Threads to LWPs. Finally, going to the one-to-one model
with the "alternate" libthread on Solaris 8 (and running on Solaris 9), we've found
the best performance, an increase of 15% over LWP synchronization, and nearly a factor
of 8x over the standard model with thread based synchronization. This may not be typical,
but shows the extreme sensitivity on a heavily threaded application.
Here's a table of results on various Solaris boxes, all running Solaris 8 with JVM 1.3.1:
| Architecture | Cpus | Threads | Model | %diff in throughput (against Standard Model) |
| Sparc | 30 | 400/2000 | Standard | --- |
| Sparc | 30 | 400/2000 | LWP Synchronization | 215%/800% |
| Sparc | 30 | 400/2000 | Bound Threads | -10%/-80% |
| Sparc | 30 | 400/2000 | Alternate One-to-one | 275%/900% |
| Sparc | 4 | 400/2000 | Standard | --- |
| Sparc | 4 | 400/2000 | LWP Synchronization | 30%/60% |
| Sparc | 4 | 400/2000 | Bound Threads | -5%/-45% |
| Sparc | 4 | 400/2000 | Alternate One-to-one | 30%/50% |
| Sparc | 2 | 400/2000 | Standard | --- |
| Sparc | 2 | 400/2000 | LWP Synchronization | 0%/25% |
| Sparc | 2 | 400/2000 | Bound Threads | -30%/-40% |
| Sparc | 2 | 400/2000 | Alternate One-to-one | -10%/0% |
| Intel | 4 | 400/2000 | Standard | --- |
| Intel | 4 | 400/2000 | LWP Synchronization | 25%/60% |
| Intel | 4 | 400/2000 | Bound Threads | 0%/-10% |
| Intel | 4 | 400/2000 | Alternate One-to-one | 20%/60% |
| Intel | 2 | 400/2000 | Standard | --- |
| Intel | 2 | 400/2000 | LWP Synchronization | 15%/45% |
| Intel | 2 | 400/2000 | Bound Threads | -10%/-15% |
| Intel | 2 | 400/2000 | Alternate One-to-one | 15%/35% |
As you can see, this experiment on 2 and 4 cpu boxes yielded quite different results. LWP Synchronization was the best on 2 cpus and the "alternate" thread library was the same as LWP Synchronization with 4 cpus. Using bound threads continued to show either no gain or a significant decrease in throughput. Going to only 400 threads on a 2 cpu box showed that LWP Synchronization was on par with the standard model, Bound threads cost 30% and the Alternate Libthread cost 10%. On a 4 cpu Solaris Intel box we saw similar results to the Sparc box, but with bound threads performing better and showing little to no degredation over the standard model.
Finally, we also seen more predicitibility by shying away from the standard model with thread based synchronization. Variability due to thread starvation seems to disappear when moving to any other model.
The default thread stack size is quite large: 512kb on Sparc and 256kb on Intel for 1.3 and 1.4 32-bit VMs, 1mb with the 64-bit Sparc 1.4 VM; and 128k for 1.2 VMs. If you have many threads (in the thousands) then you can waste a significant amount of stack space. The minimum setting in 1.3 and 1.4 is 64k, and in 1.2 is 32k, which you can change via the -Xss flag.
TLEs (in 1.3) or TLABs (in 1.4) are thread local portions of the heap used in the young generation (see the HotSpot Garbage collection Tuning Document). These offer excellent speedups on smaller numbers of threads (100s), but when moving up to larger numbers of threads the thread local heap can consume a significant amount of the total heap, so much so that garbage collection may occur more frequently. You can turn off thread local heaps completely with -XX:-UseTLE in 1.3 and -XX:-UseTLAB in 1.4. Alternatively you can size the thread local heap with -XX:TLESize=<value> in 1.3 and -XX:TLABSize=<value> in 1.4. Please note that TLEs/TLABs are only on by default in the Sparc -server JVM.
Garbage collection can radically affect performance as well. Please see the document on tuning garbage collection
ISM, or Intimiate shared memory, can also be used to boost the performance of memory intensive applications. This is a highly specialized option, and needs a few operating system parameters to be set in order to enable it, but can provide an additional 10% or more performance. Please see Big Heaps and Intimate Shared Memory for more details.
Choosing a different Solaris threading model may have an impact on your performance. The 1.3 and 1.4 VMs give you a myriad of options to choose from so that you can determine what's best for your application. The default model in 1.3, although generally fine, is not the best for applications with large numbers of threads or cpus. Our suggestion is to try various threading models if your application contains more than one thread. Also, make sure that you look at other factors that could affect your performance when your attempting to scale to larger numbers of threads or cpus.